

Step 3 Motif and Domain Analysis in Genome-Wide Analysis of Gene Families
Introduction to Gene Families
Gene families are crucial components of genomic organization, representing clusters of related genes that have originated from a common ancestral gene through the processes of duplication and divergence. The formation of these families occurs primarily via mechanisms such as gene duplication, where an existing gene is copied, followed by mutations that lead to functional diversification of the new gene copies. This evolutionary event is significant because it contributes to the expansion of gene functions, enabling organisms to adapt and evolve in response to varying environmental pressures.
The significance of gene families in genomics cannot be overstated. They play a pivotal role in elucidating the functional complexities of genomes, as each member of a gene family may perform distinct yet related biological roles. This functional specialization allows for increased versatility within biological pathways, providing organisms with the ability to harness various physiological processes effectively. Consequently, the study of gene families offers insights into organismal diversity, showing how complex traits and adaptations have developed across different lineages.
Analyzing gene families is essential in understanding evolutionary relationships among species. Through comparative genomics, researchers can identify conserved gene families across different organisms, which are indicative of shared evolutionary history. By examining gene family expansions or contractions, scientists can infer the evolutionary pressures that have shaped specific traits and functions in various taxa. Additionally, gene family analysis provides valuable information in functional genomics, aiding in the interpretation of gene functions and their regulatory mechanisms. This understanding can further enhance our knowledge about disease mechanisms, development, and overall biology.
What is Motif Analysis?
Motif analysis is a vital aspect of genomic research focused on identifying and understanding short, recurring patterns within DNA, RNA, or protein sequences that have significant biological functions. These motifs can manifest as specific sequences that are crucial in various biological processes, such as transcription regulation, protein-protein interactions, and enzymatic functions. Recognizing these motifs allows researchers to elucidate the roles of different gene families and their contributions to an organism’s overall functionality.
Among the most important types of motifs analyzed are transcription factor (TFs) binding sites and protein domains. TFs binding sites are specific sequences where regulatory proteins can bind to initiate or suppress gene expression, meaning they play a crucial role in gene regulation. Similarly, protein domains are contiguous segments of amino acids that are associated with particular functions, allowing for an understanding of how proteins evolve and interact within the cell.
To identify motifs within large genomic datasets, several computational methods and tools are utilized. Approaches such as sequence alignment, hidden Markov models, and heuristic algorithms help researchers pinpoint motifs with precision. These techniques can distinguish motifs from noise within the data, ensuring that the identified patterns are biologically relevant. Additionally, software solutions like MEME Suite and FIMO have become invaluable in motif discovery, enabling comprehensive analyses while handling extensive genomic information.
The importance of motif analysis extends beyond mere identification. Understanding these recurring patterns contributes significantly to our knowledge of gene regulation and protein function. By recognizing the specific motifs that govern interactions between regulatory elements, scientists can decipher complex biological networks and provide insights that may lead to advancements in fields such as medicine, biotechnology, and evolutionary biology.
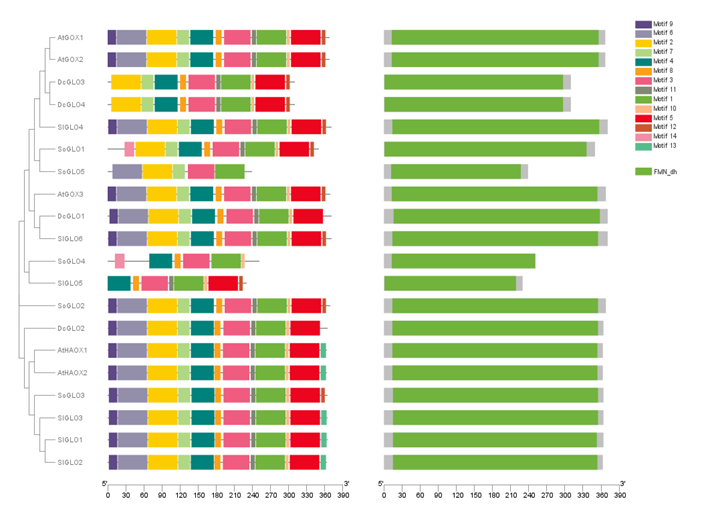
Understanding Domain Analysis
Domain analysis plays a pivotal role in the study of gene families by focusing on the distinct functional and structural units within proteins known as protein domains. A protein domain is a conserved part of a protein’s sequence that can evolve, function, and exist independently of the rest of the protein. This structural characteristic allows protein domains to facilitate the diverse array of biochemical functions necessary for biological processes. Thus, the identification and characterization of these domains are paramount in understanding the complexities of gene families.
Various computational tools and databases exist to aid researchers in domain analysis. Notably, Pfam and SMART are among the most widely used resources. Pfam is a collection of protein families, where each family is represented by multiple sequence alignments and hidden Markov models. Researchers can utilize Pfam to identify domains in protein sequences, thereby inferring potential functions and evolutionary relationships. SMART, on the other hand, provides a similar function, focusing on the identification of signaling domains and other functional regions in proteins. By employing these tools, researchers can derive insights into the structure-function relationship of proteins, offering a clearer picture of gene families.
Case studies exemplifying the contributions of domain analysis to evolutionary biology and functional genomics abound. For instance, researchers have utilized domain analysis to trace the evolutionary lineage of certain protein families, highlighting how specific domains have been conserved across species. This approach not only informs functional predictions but also enhances our understanding of evolutionary mechanisms, revealing how gene duplications and domain shuffling contribute to the diversity of life. Such analyses ultimately underscore the significance of investigating protein domains in the broader context of genomics and gene family studies.
Integrating Motif and Domain Analysis for Gene Family Research
The integration of motif and domain analysis is becoming increasingly pivotal in the field of genome-wide studies of gene families. Motifs, which are short, conserved sequences of amino acids or nucleotides, provide critical insights into the functional aspects of genes. Conversely, domains are larger structural units that are often associated with specific functions or interactions in proteins. By combining these two analytical approaches, researchers can uncover a more comprehensive picture of gene function, regulation, and evolutionary relationships.
One of the significant benefits of integrating motif and domain analysis is the enhanced ability to predict the functionality of uncharacterized genes within a gene family. For instance, a study on the plant resistance gene families demonstrated that by analyzing conserved motifs alongside known functional domains, researchers could identify potentially functional genes that had not previously been characterized. This approach not only improves gene annotation processes but also aids in understanding the evolutionary adaptations of these gene families.
Additionally, integrating motif and domain analysis has practical implications for researchers. This combined strategy can streamline the identification of gene targets for genetic modification or biotechnological applications. For example, in studies of metallothionein gene families, utilizing both motifs and structural domains led to the identification of candidate genes with enhanced heavy metal tolerance, which could be critical for developing resilient crop varieties.
Research scientists should also consider the computational tools available for effective integration. High-throughput sequencing data can be analyzed using bioinformatics software that focuses on both motifs and domains, providing a coherent framework for interpreting complex genomic data. As the field continues to evolve, fostering collaborations between computational biologists and experimentalists will be essential in maximizing the potential of gene family research through motif and domain integration.
Practicals of Motif Analysis
Now do motif analysis with the help of
- You need 4 files
- FASTA file of all Protein sequences of specific gene family member
- Phylogenetic Newick file of all Protein sequences of specific gene family member
- Meme
- Hit data
- Goes to meme suit (web).https://meme-suite.org/meme/
3. Click on the MEME Suite

4. Paste your peptide
5. Scroll down and change motifs number to And start.
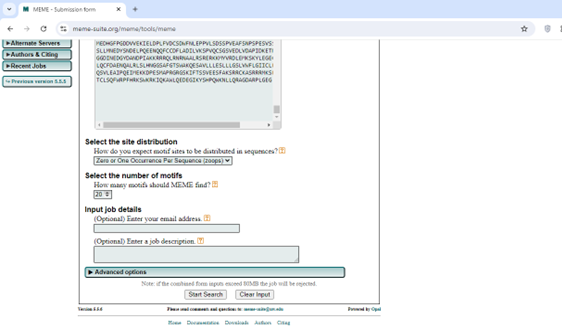
6. Download the meme XML
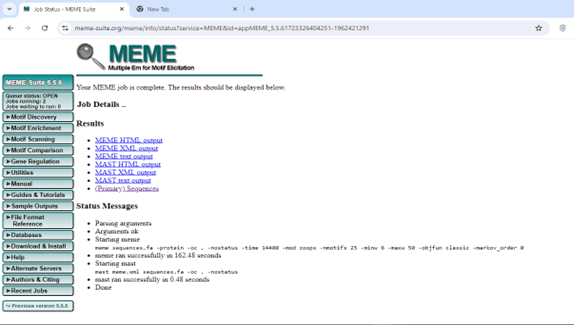
7. Now for the 4th file go to NCBI CDD
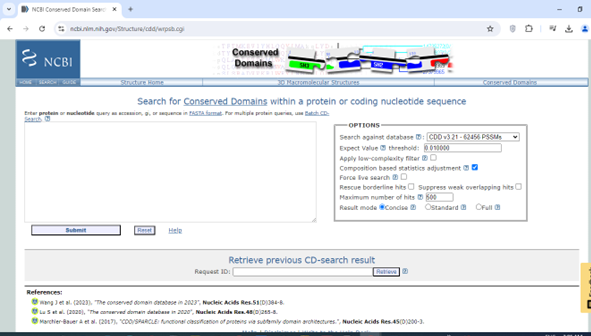
8. Select pfam data

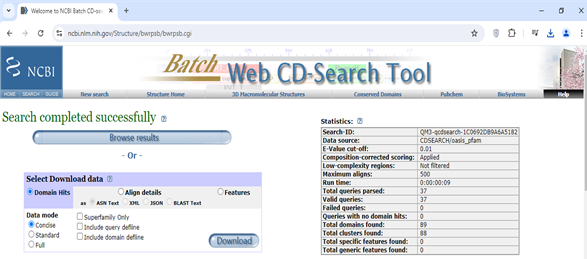
9. Paste peptide sequences

10. Download the file (Hit data).
10. Now go to Tbtools and follow the below


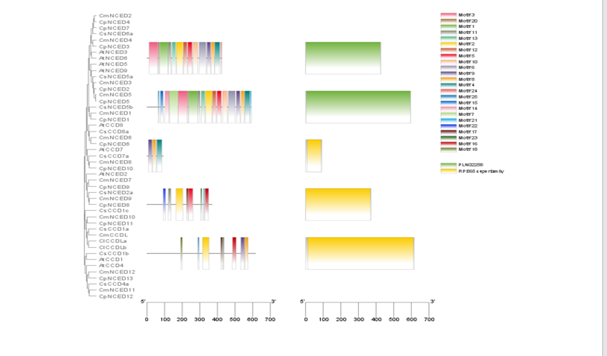
For Other Steps Please follow
Step 2 Phylogenetic analysis roles in the classification and evolution of Gene Family Members




Domains In Omics: Insights Into Genomics, Proteomics, And Functional Biology -
[…] of omics, which encompasses genomics, proteomics, transcriptomics, and metabolomics, the study of domains is essential for understanding how biological molecules function and interact. Domains are distinct […]